Series Introduction
We are going to have a deep dive into the world of indexes in a series of posts that will cover the following topics:
-
-
- What are indexes, why to use them and how they are being implemented?
- The different types of indexes.
- Indexes in relational databases.
- Indexes in NoSQL databases.
- Common tips for good indexing strategy.
-
Part 1: Why indexes? .. or what is the problem?
Before we start providing a definition to indexes, we need first to define what kind of problem we have that led to inventing such thing in relational databases and relational database management systems.
Historically, and since the invention of computers and database systems, data is always bigger in size when compared to machines resources, and this problem is getting more complex as data keeps growing and growing over time.
In database and information systems world, we need in a certain point of time “perhaps most of the time” to view the data we keep inserting into our databases, reporting activities and analytics processes are essential for business to make use of data for business decisions, business applications, ERP systems, web and mobile applications also need to read data in a certain point of time for different purposes.
Another important point to mention here is the way data being read and written in database management systems, data is always stored on disk as a persistence storage, however when it is being read or written it exists in memory as a transit stage between the application deals with data and storage that saves this data, it also worth mentioning that CPU is responsible for moving data between storage and memory.
Based on all the above, it makes sense that reading a big amount of data stored on disk will consume a big amount of memory, also requires intensive CPU handling to move this data, and finally will lead to retrieve this data in amount of time longer than expected with long running database transactions leading to database and database server bad performance.
All the above symptoms construct the real problem that indexes come to solve, and in the next section we will go to check how indexes can do that.
Before moving to the next section, let us summarize the problem definition section: Indexes help reducing the amount of data being retrieved from databases which has a positive effect on databases and database servers performance.
Part 2: How indexes solve the problem?
In order to understand how indexes can solve the problem we discussed above, we first need to understand how database management systems “DBMS” store our data, DBMSs designed to store data or rows of data into pages or blocks with fixed size, the single data page can hold one or more rows for a certain table in a certain database, so it is important to understand that when querying a database table to retrieve a bunch of records the DBMS then copy all records related pages from disk into memory “this leads in most of the time to have some unwanted records being copied into memory as long as they share the same pages with the records we want to read”, and by default the more pages the engine reads the more memory space, CPU power and disk IO operations required “hence our target is to read the data we want while copying and navigating into the least number of pages – which is the idea behind using index”.
So, to give a simple example, let us assume that we need to get some information related to a certain customer in our database, and customer data is stored in “Customers” table, and we are searching for customer with ID number 400 and need to return customer name and address, the default way the database engine will use to get this information is by scanning the whole table pages “reading them from disk –> copying them into memory” till reaching the customer with ID number 400 and fetch the required page, please note that all data pages the engine scanned till reaching ID 400 have been copied from disk into memory “this is also under the assumption that these pages are not present in memory as a result of an earlier query scanned the same pages before – in such case there the DB engine will read these pages directly from memory and not from disk”.
Back to the main question, how indexes solve the problem or how indexes make the database engine reads the least number of pages?, the answer is by indexing our tables or by creating a special data structure beside the main table itself that the engine can use to navigate and then point directly to the pages in the main table “the table we read data from”, this is a general idea that applies to any type of indexes invented in any type of database management system.
Back to the above example for querying customer with ID number 400, in case of having an index created on customer ID column, then the DB engine will start navigating the index pages searching for index with value 400 then jump to the base table pages fetching the required page “scanning less number of pages by far when to compare to the original method above without having indexes”.
The below drawing illustrates this idea “please note that this drawing is very simplified in sake of delivering the main idea of indexes and it is not representing the real table and index internal structure“:
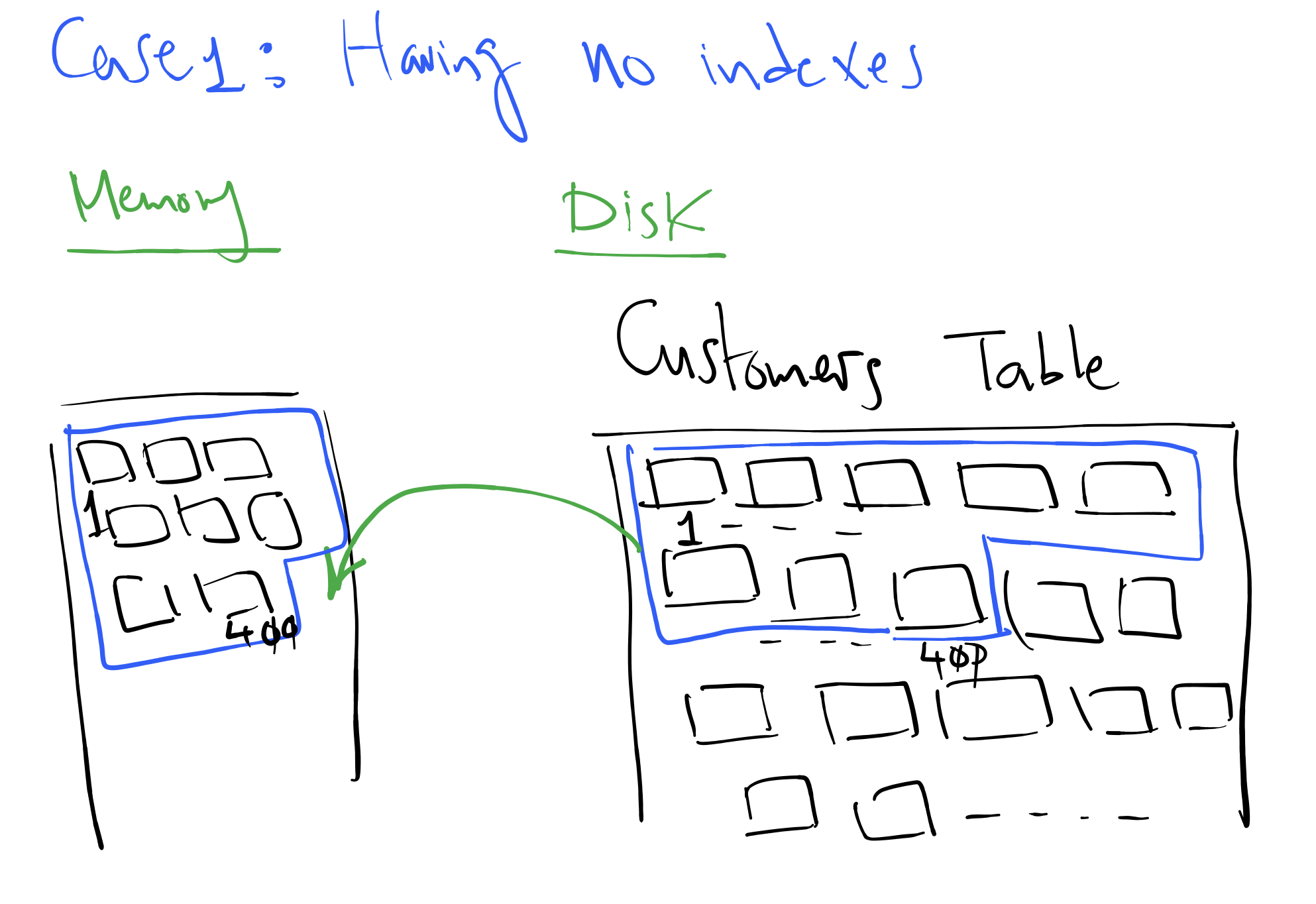

We can easily recognize the difference in the amount of pages being copied from disk to memory in order to fulfil querying customer name and address for ID 400 between having no index and having an index on customer id column.
This mechanism is very closed or identical to the idea of using index in phonebook, in order to get the number of my friend “Tamer”, I need to perform one of two actions:
-
-
- Scan all phonebook pages till reach the letter “T” page and search for “Tamer”.
- Scan the phonebook index starting from letter “A” till reach letter “T” then open letter “T” page and search for “Tamer”.
-

Part 3: Index definition
After we stated the problem definition of why indexes are being used and how they are able to solve it, I think it will be easy to provide a definition of what indexes are, and we can simply define an index as:
A database index is a data structure that improves the speed and efficiency of data retrieval operations in a database management system (DBMS). It is used to quickly locate and access specific data records within a database table.
What is next?
In the next post we will start getting deep into indexes, defining the different type of indexes and how indexes are being implemented in different database management systems for both relational and NoSQL database systems.

Leave a comment